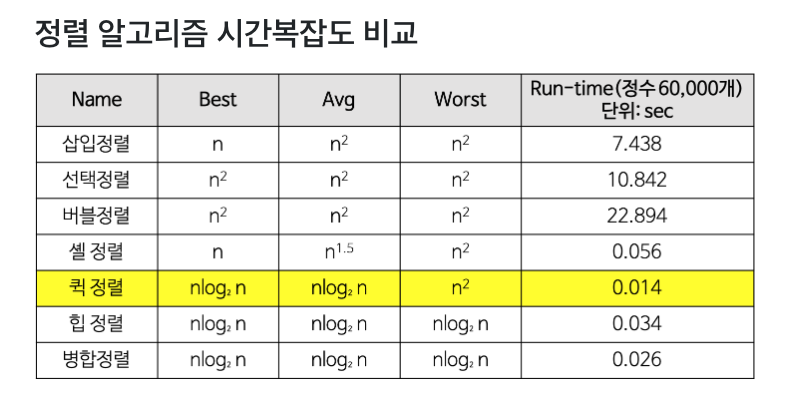
시간복잡도 : 평균 - O(NlogN) , 최악의 경우 O(N^2) --> 이미 정렬이 수행이 되어 있는 경우. (1 2 3 4 5 6 7 8 9 10)
결과적으로 이미 정렬이 되어 있는 경우에는 삽입정렬 알고리즘이 매우 빠르게 풀어 낼 수 있다.
기준 데이터를 설정하고 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방법
가장 많이 사용되는 정렬 알고리즘이고, 프로그래밍 언어의 정렬 라이브러리의 근간이 되는 정렬 방법
이진탐색과 비슷한 방법이다.
#include <bits/stdc++.h>
using namespace std;
int n = 10;
int target[10] = {7, 5, 9, 0, 3, 1, 6, 2, 4, 8};
void quickSort(int *target, int start, int end)
{
if (start >= end) return;
int pivot = start;
int left = start + 1;
int right = end;
while (left <= right) // 엇갈릴 때 까지 반복
{
// 키 값 보다 큰 값을 만날때까지
while (left <= end && target[left] <= target[pivot]) left++;
// 키 값보다 작은 값을 만날때까지
while (right > start && target[right] >= target[pivot]) right--;
// 엇갈린 상태라면 pivot 값과 교체
if (left < right) swap(target[pivot], target[right]);
// 엇갈리지 않았다면 큰 값과 작은 값을 교체
else swap(target[left], target[right]);
}
// 데이터가 엇갈려서 while문을 빠져나온다면 pivot 값을 기준으로 왼쪽과 오른쪽에 대해서 퀵정렬을 수행한다.
quickSort(target, start, right - 1);
quickSort(target, right + 1, end);
}
int main(void)
{
quickSort(target,0,n-1);
for (int i=0; i<n; i++)
{
cout << target[i] << ' ';
}
return 0;
}
pivot은 기준 값이다. pivot은 첫 번째 원소이다.
퀵정렬은 재귀적으로 수행이 된다.
퀵정렬의 경우 위의코드는 오름차순 코드인데, 내림차순으로 바꾸려면
첫 while문 뒤의 2개의 while문에 있는 조건식의 부등호 방향만 바꿔주면 내림차순 코드가 된다.
결론 - 일반적으로는
버블정렬 < 선택정렬 < 삽입정렬 < 퀵정렬 순으로 선호된다.
하지만 결과적으로는 데이터의 특성에 따라서 적절한 정렬 알고리즘을 사용하는 것이 중요하다.
예를들어서 이미 정렬 된 데이터의 경우 퀵정렬보다 삽입정렬이 더 빠르게 풀어낼 수 있기 때문이다.